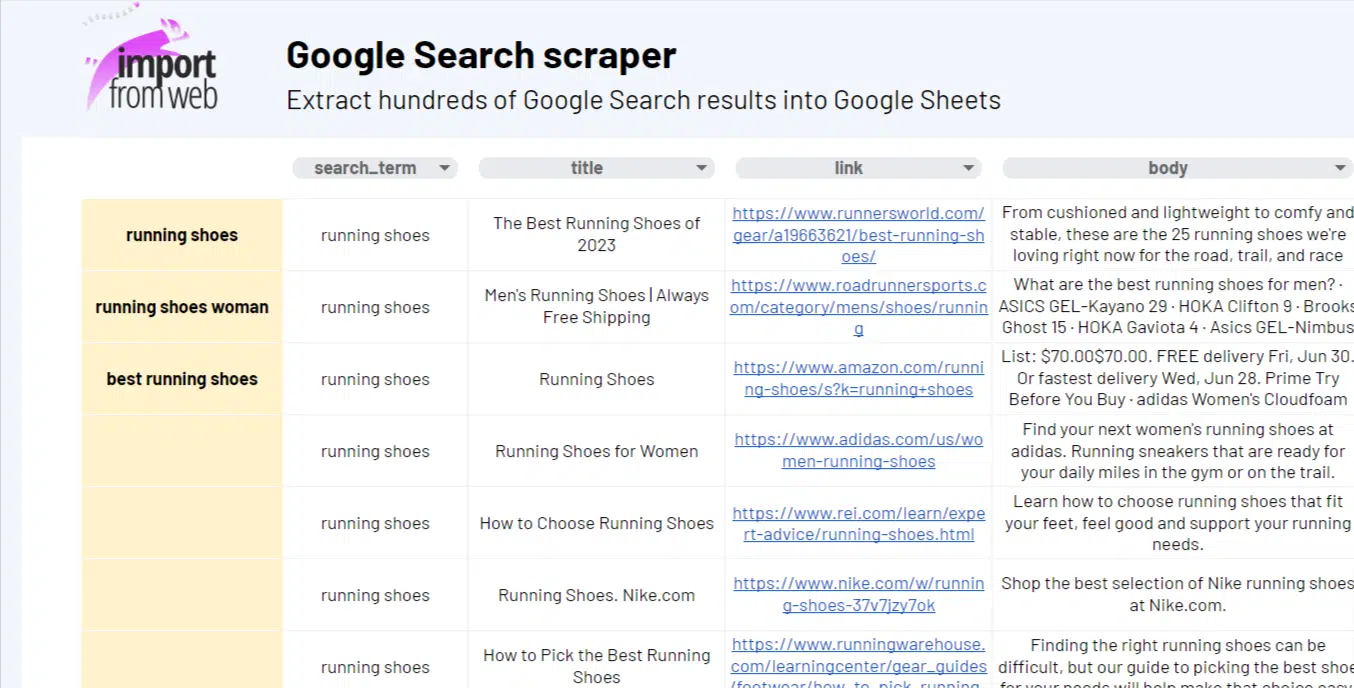
Google Search plays a central role in our digital lives, providing a gateway to the vast information available on the internet. It serves as a powerful tool for research, entertainment, shopping, and more. Businesses rely on it to enhance their online presence, drive website traffic, and connect with their target audience through search engine optimization (SEO) strategies.
Our no-code scraping solution offers time savings, customization options, seamless integration with Google Sheets, and the ability to obtain real-time data updates. Maximize your research capabilities and gain valuable insights with this powerful scraping tool.
Using the ImportFromWeb add-on and the function it adds to Google Sheets, you can extract your Google Search Results in bulk without technical knowledge!
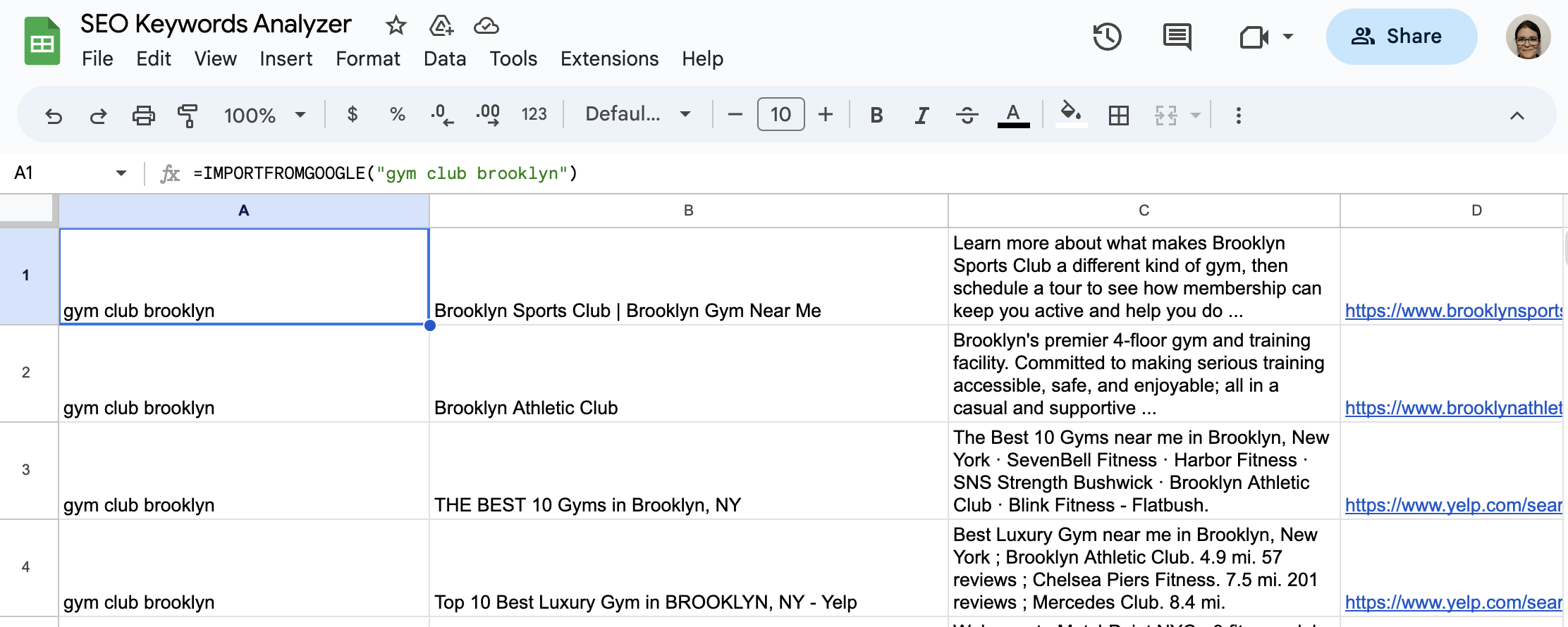
Let’s retrieve the organic results for “gym club Brooklyn”.
This is the formula we need: =IMPORTFROMGOOGLE("gym club brooklyn")
Within seconds, you’ll get the following data points for your results: title, description, and webpage’s URL. Google may also include the publication date and the rating for some pages. For a full list of available data selectors, check out our Google Search selectors glossary.
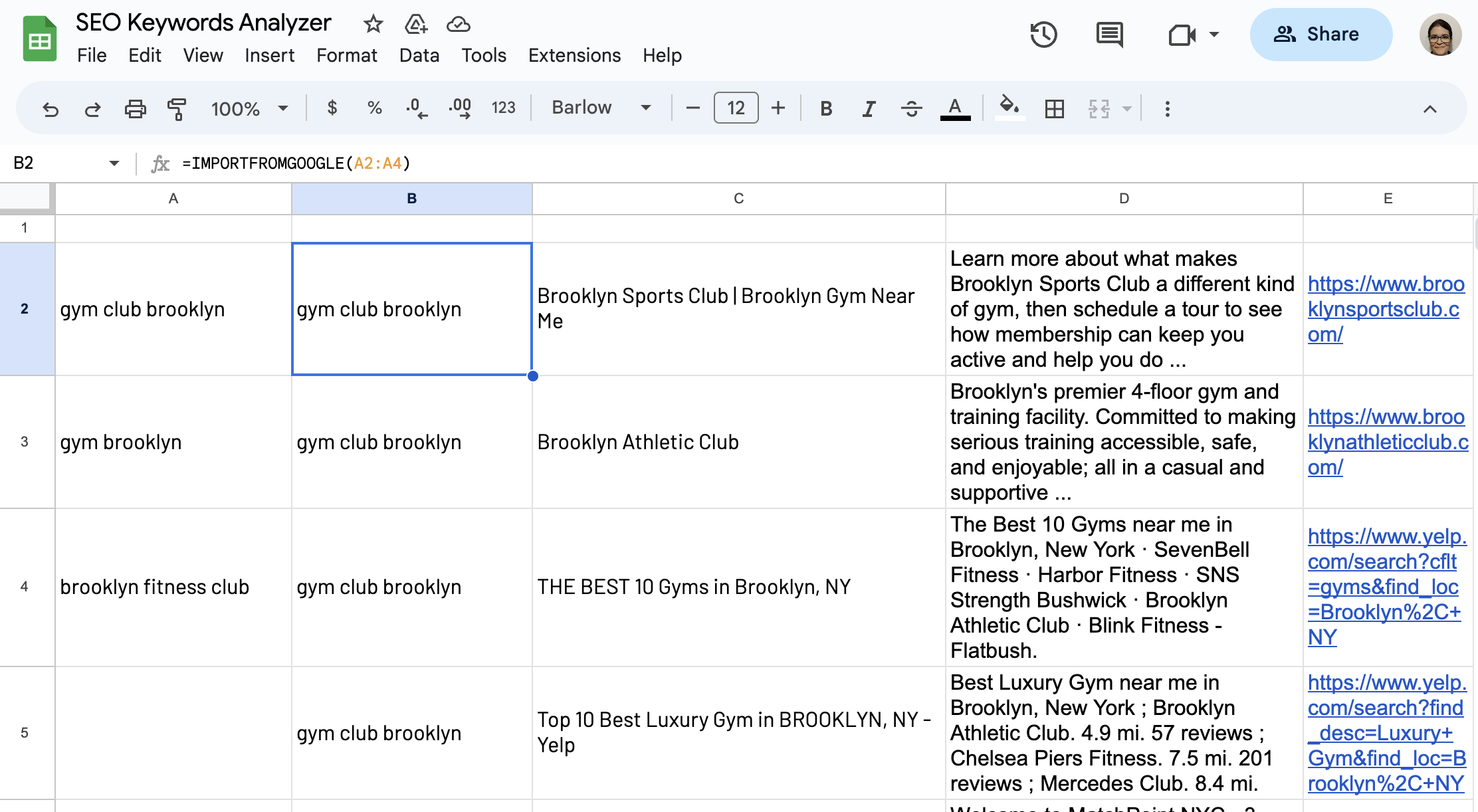
The =IMPORTFROMGOOGLE() function can retrieve results for up to 50 sets of keywords! To collect data for multiple keywords, write them separated by commas or select a range of cells containing them:
The function has additional features which allow you to collect data using different options. You can specify these criteria using the function’s third parameter: options.
Specify the number of results
By default, the function displays the first 10 Google results. However, you can specify the exact number of results you want to retrieve, whether it’s only the first or the first 300.
For example, if you only want to retrieve the first result, use the following formula:
=IMPORTFROMGOOGLE("gym club brooklyn","title,body,link","num_results:1")
Choose the Google domain and results language
Our ready-to-use template is set to search within google.com, but you can change this setting to any domain you want.
The following example retrieves results from google.fr:
=IMPORTFROMGOOGLE("gym club brooklyn","title,body,link","domain:.fr")
Likewise, you can restrict the results to websites in a specified language.
The following example retrieves results in English only:
=IMPORTFROMGOOGLE("gym club brooklyn","title,body,link","languages:en")
Use “period” to filter by publication date
The “period” option allows you to filter the websites collected by publication date. You can select results from the past hour, the past 24 hours, the past week, the past month, or the past year.
For example, use this formula to retrieve results published in the past year:
=IMPORTFROMGOOGLE("gym club brooklyn","title,body,link","period:year")
Combine options
You can combine several options within the same function, like in the example below:
=IMPORTFROMGOOGLE("gym club brooklyn","title,body,link","domain:.fr,numResults:50")
We’ve designed an easy-to-use template to extract Google Search results. Make sure you have installed and activated ImportFromWeb in your Google Sheets.
By default, the =IMPORTFROMGOOGLE() formula returns the first 10 organic results from Google Search on any query.
To retrieve only the first result, you can use the num_results option as a 3d parameter of your function. This option allows to specify the number of results to extract for each keyword.
And here’s the formula to retrieve the first Google Search result:
By default, the =IMPORTFROMGOOGLE() formula returns the first 10 organic results from Google Search on any query.
To extract more than the initial 10 results, you can use the num_results option within the IMPORTFROMGOOGLE formula. This option allows you to specify the number of results to be extracted for each keyword.
Here’s an example formula to retrieve the first 100 results:
Please note that the maximum value accepted is 300. And this 300 records cap is set by Google itself (by the way, when you search on Google, you get a maximum of 30 pages with up to 10 records per page).
It’s important to note that the number of results you receive through IMPORTFROMGOOGLE is determined by Google itself and can vary based on several factors. Sometimes, Google displays widgets or other elements alongside search results, affecting the count and presentation of organic results.
This variation can result in cases where the expected 10 results might not be returned or where some results appear to be missing.
If obtaining precisely the top 10 results is crucial, utilizing an ARRAY_CONSTRAIN formula can be an effective solution. This function allows users to limit the number of rows and columns in the returned array, ensuring precise control over the displayed results.
No, IMPORTFROMGOOGLE function specifically extracts organic search results and does not support scraping Google Ads or paid results. So it only retrieves information from the organic search listings on Google.
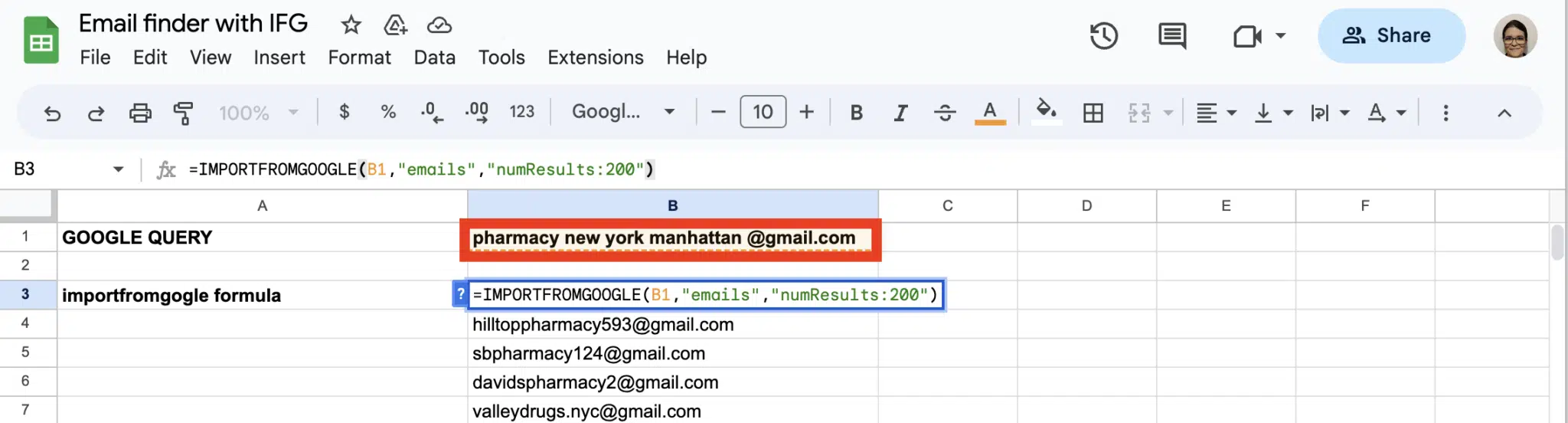
Absolutely! With ImportFromWeb, you can extract emails from websites using our list of generic selectors, which includes emails.
Here’s the formula you have to write: =IMPORTFROMWEB("https://www.example.com", "emails")
Just bear in mind that while these selectors are designed to work with a wide range of websites, the success of email extraction may vary depending on whether the websites follow general guidelines for design and data presentation.
Another way of getting emails is to use the IMPORTFROMGOOGLE function to perform a boolean search and extract the emails: =IMPORTFROMGOOGLE("search_terms","emails")
The Google Search Results depend on multiple factors like user location, search history, and personalization settings. Because of this, it can happen that the results you see on the Google Search page differs from the results that you get with IMPORTFRFOMGOOGLE. The results won’t be completely different but you might notice some minor differences.
The best you can do to approximate the SERP you have is to use the full URL in the IMPORTFROMGOOGLE function.
IMPORTFROMGOOGLE can retrieve Google Search autocomplete suggestions for a keyword by utilizing a specific selector designed for this purpose. Simply use “suggestions” as the second parameter within the =IMPORTFROMGOOGLE() function:
=IMPORTFROMGOOGLE("your query", "suggestions")
For a ready-to-use Google Sheets template, visit our page: Google Suggest Scraper. It provides easy access to extract autocomplete suggestions efficiently.
IMPORTFROMGOOGLE has a dedicated selector to retrieve Google People Also Ask questions related to a keyword. You can utilize this feature by using “people_also_ask_questions” as the second parameter within the IMPORTFROMGOOGLE function.
You can also access our Google People Also Ask Question Scraper. This resource provides a ready-to-use Google Sheets template facilitating the extraction process.
To retrieve Google Related Searches associated with a keyword, IMPORTFROMGOOGLE offers a specific selector that facilitates this extraction. You can use “related_searches” as the second parameter within the IMPORTFROMGOOGLE function.
By incorporating this function, you can effortlessly extract Related Searches directly into your Google Sheets. Please note that typically, the number of related searches displayed is limited to 8.