
Google Search
Google Search Scraper
Extract Google Search Results into Google Sheets.
Google Search
Google People Also Ask Scraper
Extract Google People Also Ask questions directly into Google Sheets.
Google Search
Social Media Profile Finder
Find social media profiles from a list of companies / names.
Google Search
Google Suggest Scraper
Extract search queries which are suggested by Google when users type in a search
Google Search
Google Keywords Ranking Tracker
Track and monitor your organic rankings on a set of keywords with Google Sheets
Google Search
Domain Name Finder
Extract the domain name for multiple companies or brands
Google Search
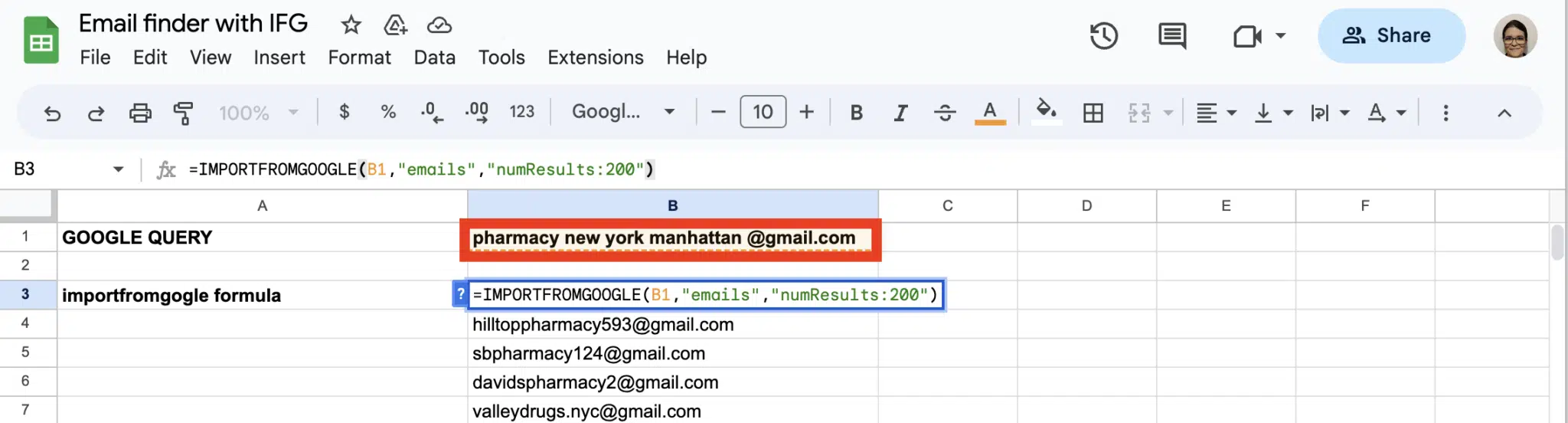
Email finder
Extract hundreds of emails into Google Sheets with a simple query
Google Search
Google Related Searches scraper
From a keyword, get the related searches from Google SERP
Frequently Asked Questions
Is it legal to scrape Google?
Scraping Google using =IMPORTFROMGOOGLE() is based on publicly available information. The function accesses data that is openly accessible on the internet. And generally, accessing and scraping publicly available data from websites is considered legal.
Moreover, with IMPORTFROMGOOGLE, the scraping is made using multiple premium proxies and external rotating IP addresses, so you do not have to worry about the possibility to be banned from scraping Google Search results.
Nonetheless, it remains important to stay informed about the terms and conditions set by Google and exercise scraping responsibly and ethically.
Is there a way to extract emails from websites?
Absolutely! With ImportFromWeb, you can extract emails from websites using our list of generic selectors, which includes emails.
Here’s the formula you have to write: =IMPORTFROMWEB("https://www.example.com", "emails")
Just bear in mind that while these selectors are designed to work with a wide range of websites, the success of email extraction may vary depending on whether the websites follow general guidelines for design and data presentation.
Another way of getting emails is to use the IMPORTFROMGOOGLE function to perform a boolean search and extract the emails: =IMPORTFROMGOOGLE("search_terms","emails")
How many results can I scrape from Google Search using ImportFromWeb?
The maximum number of results that =IMPORTFROMGOOGLE() can retrieve from Google Search on a specific query is determined by Google, typically around ±200 results. Unfortunately, this limit is set by Google and cannot be altered.