Extract Google results is a widely used technique to retrieve data and analyse them to take better decisions. The uses are innumerable:
- Know the rank of your website with regard to several keywords
- Understand your environment by analyzing the websites that rank best and follow the positions of competitors
- Analyze the most effective content
- Understand the keywords and sentence formulations that work best
And obviously, there’s nothing like our good old spreadsheet to process and manipulate data extracted. In short, Google Search Scraper + Google Sheets is a marketers’ paradise!
In this tutorial, you will discover the ultimate step-by-step guide to generating a table of thousands Google results in Google Sheets. You can also refer to our Google Search Scraper template on Google Sheets.
To collect data from Google SERPs, we will use the function =IMPORTFROMGOOGLE() that is available in any spreadsheet once ImportFromWeb add-on is activated.
How to use =IMPORTFROMGOOGLE() function?
To collect data with =IMPORTFROMGOOGLE() nothing more simple:
Primarily, make sure the add-on is installed and activated within your spreadsheet.
Then, you must first input a keyword (or a key sentence) which you want to get the results from Google SERP. You can write it into quotation marks or by specifying the cell containing it, as follow:
=IMPORTFROMGOOGLE("rental car")
By default, the function displays the first 10 Google results, containing the keyword, header, body and link to the page for each result.
To collect the data for multiple keywords, just write the keywords separated by commas, or select a range of cells containing the keywords, as follow:
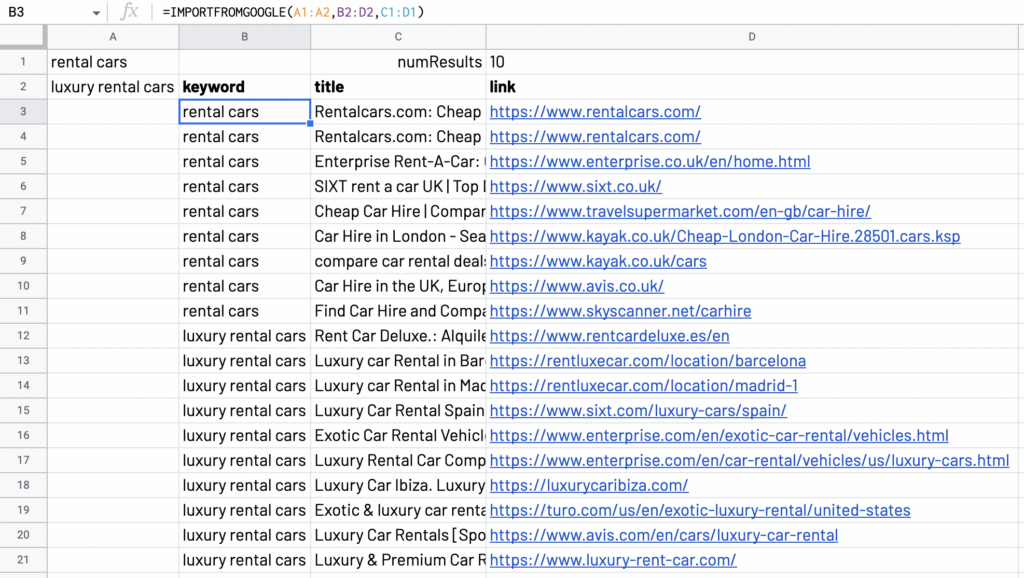
You can catch up to 50 keywords at a time.
You can also be interested in getting only some parts of each result (for example the link only or the meta title only). To do so, you have to input a second parameter to your function that we call selector.
Here is the list of the Google selectors:
- search_term
- title
- body
- date
The function will then be written as:
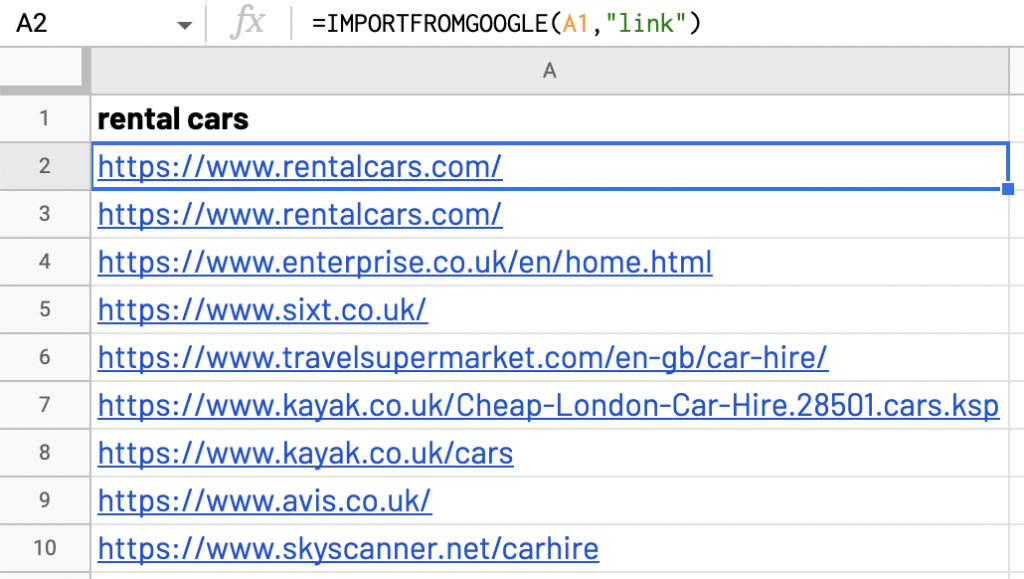
=IMPORTFROMGOOGLE(A1,“link”)
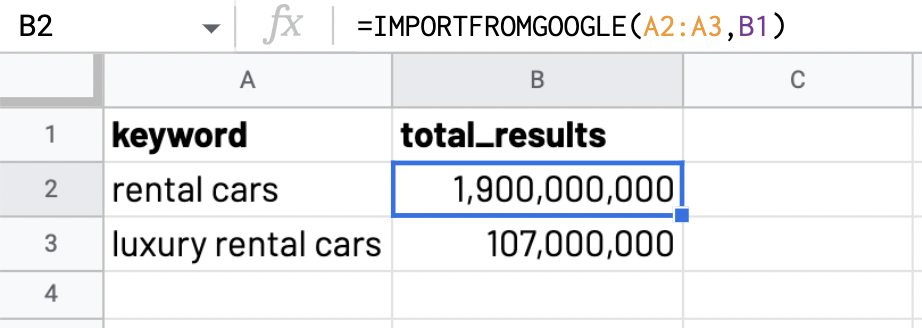
The “total_results” selector collects the number of results for the researched keyword, which can be very useful for keyword research.
The options to empower your Google Scraping
Finally, the function comes with additional features using options. They allow you to collect data using criterions and they must be imputed as a third argument within your formula:
=IMPORTFROMGOOGLE(“rental car”,“link”,”option(s)”)
Use “num_results” to set a number of results
This option allows you to extend the number of results extracted for each keyword.
To set that number, just specify it on the cell next to it and select the two cells together.
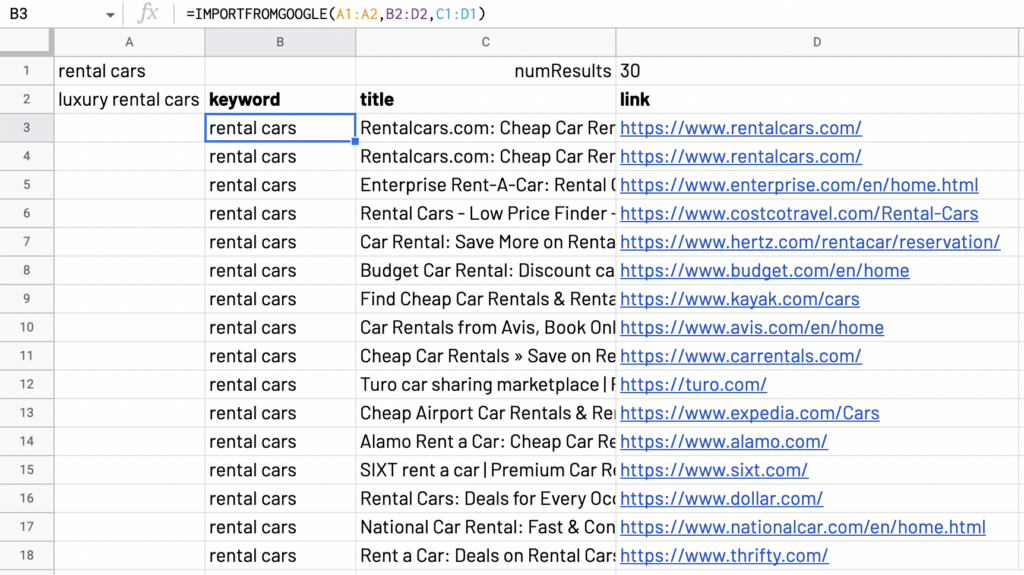
In the following example, the “numResults” set this number at 30:
=IMPORTFROMGOOGLE(A2:A3,B1:D1,C1:D1)
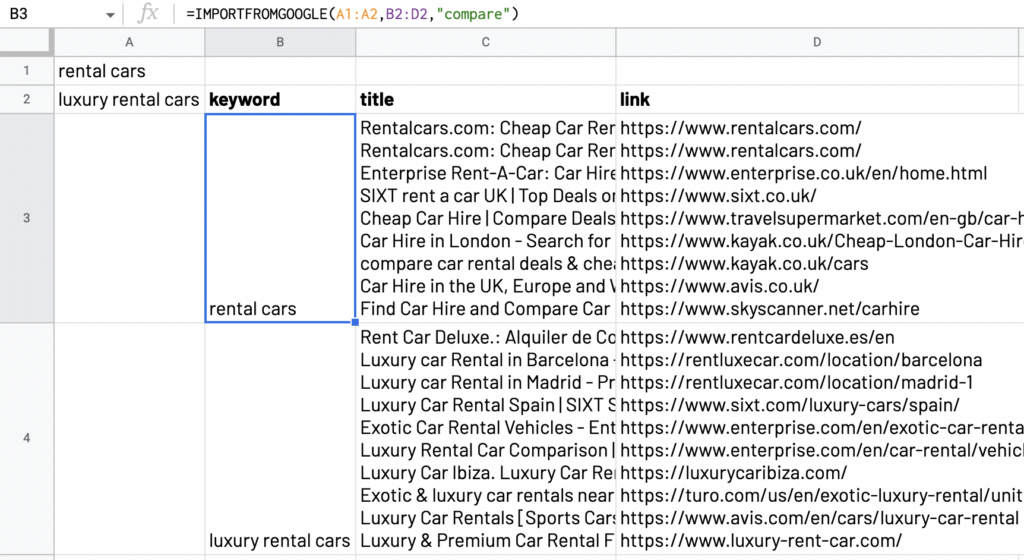
Use “compare” to organize data
If there is too much data, the spreadsheet might look disorganized and not neat. By using the option “compare”, all the data in the cells will be adapted for users to be able to read.
The function will be written as:
=IMPORTFROMGOOGLE(“keywords”, "title, link", “compare”)
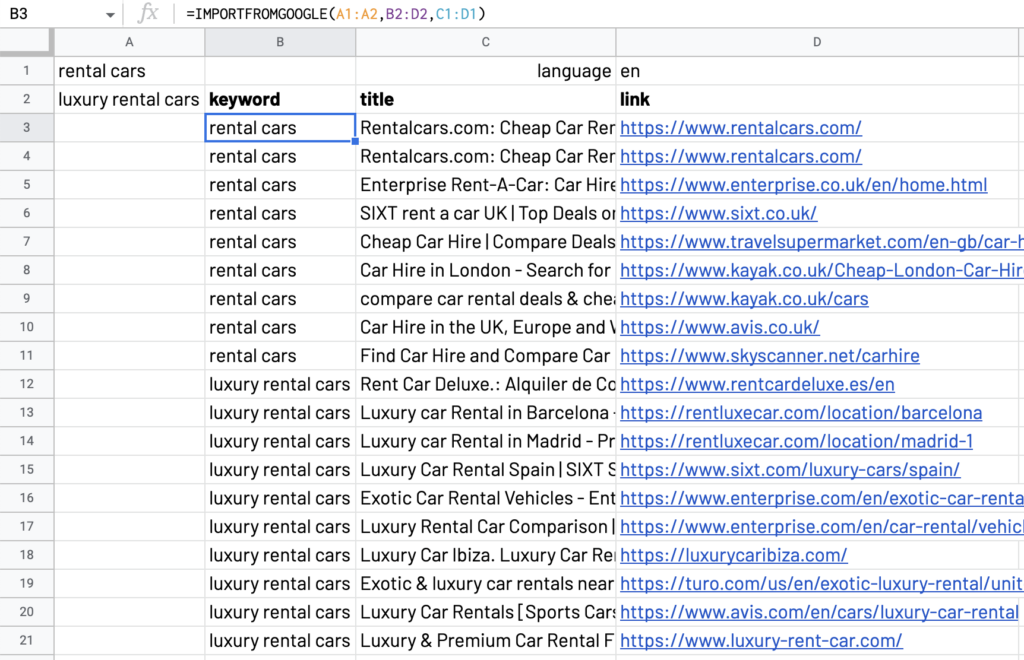
Use “languages” to collect the data to the requested language
The “languages” option allows you to restrict the results to websites in the specified language.
The example below will pull out websites in English only:
=IMPORTFROMGOOGLE(“keywords”, “selector”, “languages:en”)
Use “period” to filter according to the published date
Period allows you to filter the websites collected based to the date of publication. By using this option, you can select results from the past hour, past 24 hours, past week, past month or past year.
The function will be written as:
=IMPORTFROMGOOGLE(“keywords”, “selectors”, “period: year”).
Use “includeOmittedResults” to collect also omitted results
“includeOmittedResults” allows the function to collect data from omitted results (results not shown by google). If the data scraped takes more time than usual, do not worry!
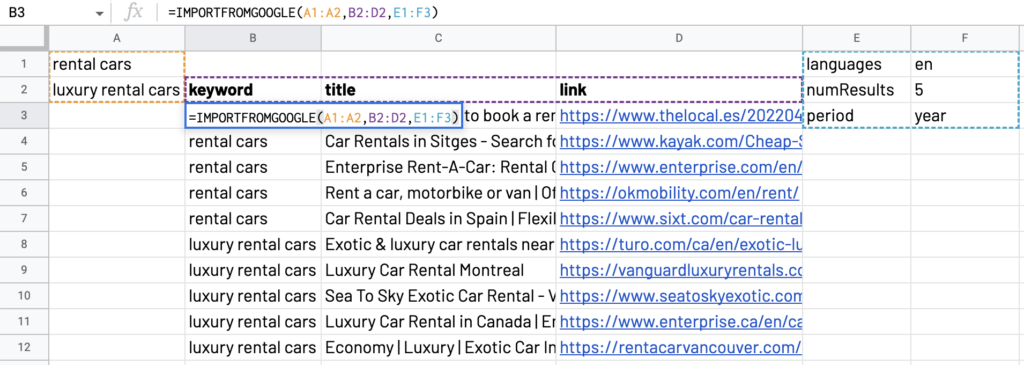
Combine options
As for keywords and selectors, you can mix several options within the same function, for example:
=IMPORTFROMGOOGLE("your keyword", "your selector", "num_results:300,compare")
Watch out our video demo!
Finally, we invite you to check our other Google Search scraping solutions to discover more use cases!
Last but not least, you can also watch our tutorial video.
If you have any doubts or any question about this function or about ImportFromWeb, do not hesitate to contact us.