4,000+ Customers Worldwide
Amapulse,
Real-time Amazon monitoring tool
Brand & Agency: Boost your digital shelf instantly
Amapulse (ex ImportFromWeb) turns spreadsheets into your go-to-platform for listing monitoring, Buy Box tracking, competitive benchmarking & more across Amazon, Walmart and any marketplaces worldwide.
Trusted by world-class companies worldwide









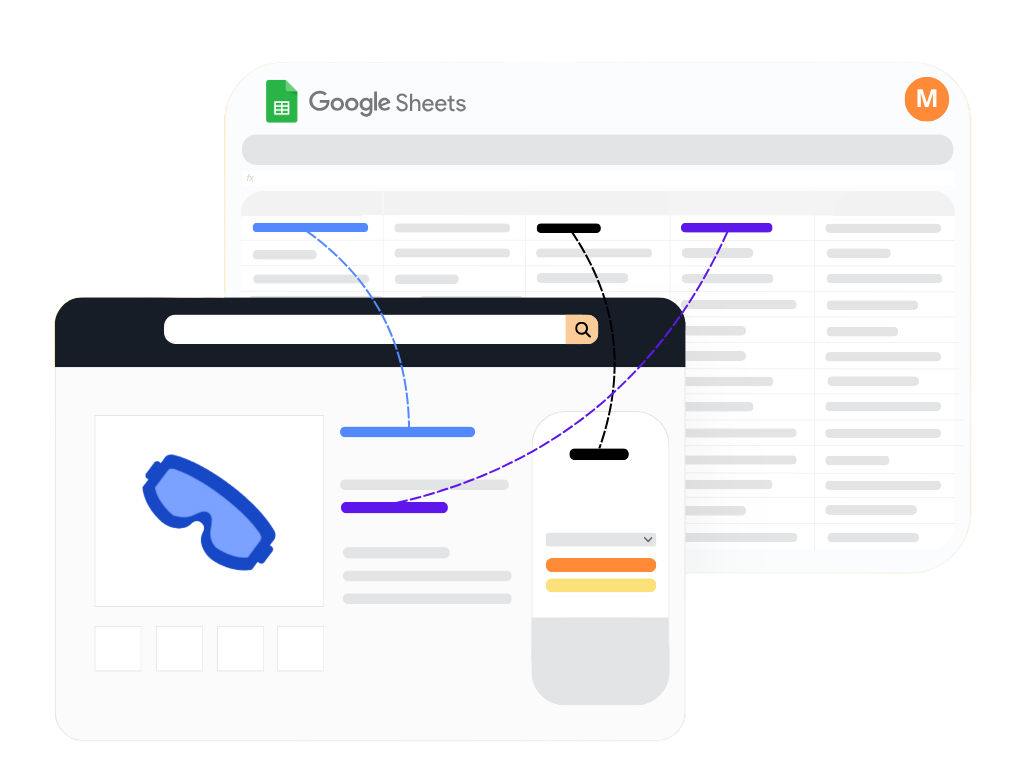
Your marketplace analytics tool
Monitor, analyze, and optimize your marketplace performance
Direct-to-sheet analysis
Connect listings and marketplace data directly into Google Sheets. What you see in your spreadsheet is what's live - no black boxes, no lag.

100% custom dashboards
Create your own monitoring tools or use pre-designed Google Sheets dashboard. Whether you need to audit listing, track Buy Box ownership, or monitor keyword rankings, getting started is quick and easy.

Seamless collaboration
Google Sheets' native sharing and collaboration features let your team work together on the same datasets in real-time.
Schedule updates & alerts
Stay updated on what matters with automated refreshes and custom alerts tailored to your workflow.
Historical data
Keep a full history of your data - uncover trends, monitor impact, and drive smarter strategic decisions.
Live Source Data
What you see in the spreadsheet is exactly what is/was live at the time - captured as historical snapshots you can reference anytime.
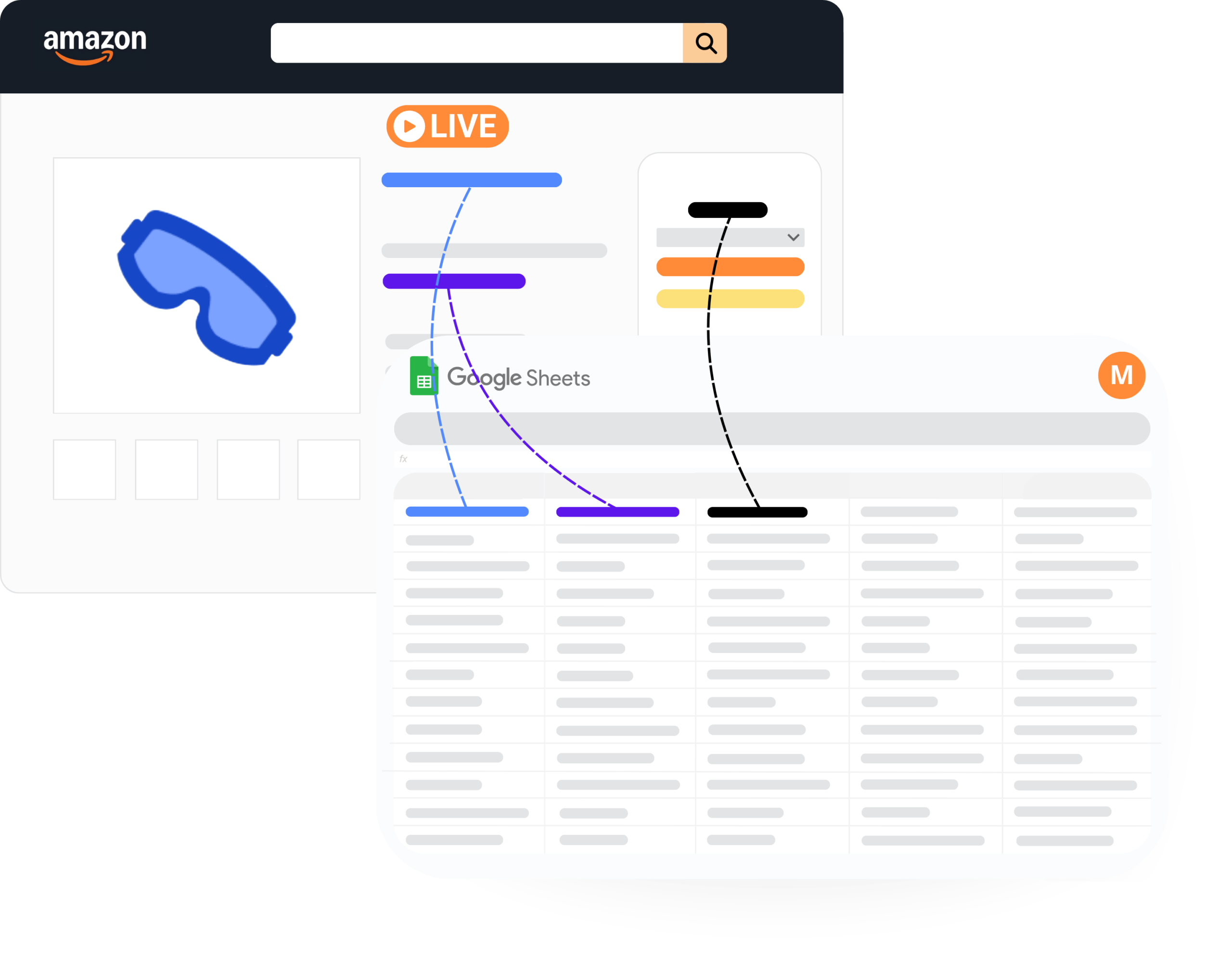
How it works
See Amapulse in action !
Want to see how Amapulse can help you boost your marketplace sales ?
Let us show you how to create a 100% custom tool based on spreadsheet and turn it into a powerful business tool for your digital shelf.
❤️ by thousands of users
A score of 4.6/5 in the Google Workspace Marketplace
Just the tool I needed to save time and money, a repetitive job that wasted at least 10 hours of my life each week now takes seconds, that's 21 days a year.
– Scott
Amapulse has been an amazing tool for me, saving me endless hours and making my data capture incredibly easy and convenient.
– Betsy
As a mere code-ignorant, I was looking around to find a solution to my scraping problem. Amapulse is a must have Google Sheets function.
– C.A.
This tool is fantastic for web scraping. The support team is responsive and helpful. 11/10 would recommend.
– Michael T.
Amapulse has transformed how we collect market data. What used to take days now takes minutes.
– Sarah
Been using Amapulse for a very long time. Stability is so good I sometimes go months without thinking about it… just works.
– Ben Webster
I just implemented Amapulse in like 5 minutes. Data in my sheets in seconds. I am sold.
– Lola
Ripped out my old solution and moved to Amapulse. The app is ridiculously easy to use and docs are great.
– Harvey
I've been so impressed since migrating almost all our data extraction. The peace of mind is amazing and the responsiveness of their support team is next level.
– Kieran Masterton
The API is solid as gold. Amapulse = 💚
– Tyson L.
Couldn't be happier with the experience. Makes web scraping accessible to everyone.
– Dan F.
I have nothing but huge love for Amapulse. A true game-changer for data collection.
– Anna M.
Just the tool I needed to save time and money, a repetitive job that wasted at least 10 hours of my life each week now takes seconds, that's 21 days a year.
– Scott
Amapulse has been an amazing tool for me, saving me endless hours and making my data capture incredibly easy and convenient.
– Betsy
As a mere code-ignorant, I was looking around to find a solution to my scraping problem. Amapulse is a must have Google Sheets function.
– C.A.
This tool is fantastic for web scraping. The support team is responsive and helpful. 11/10 would recommend.
– Michael T.
Amapulse has transformed how we collect market data. What used to take days now takes minutes.
– Sarah
Been using Amapulse for a very long time. Stability is so good I sometimes go months without thinking about it… just works.
– Ben Webster
I just implemented Amapulse in like 5 minutes. Data in my sheets in seconds. I am sold.
– Lola
Ripped out my old solution and moved to Amapulse. The app is ridiculously easy to use and docs are great.
– Harvey
I've been so impressed since migrating almost all our data extraction. The peace of mind is amazing and the responsiveness of their support team is next level.
– Kieran Masterton
The API is solid as gold. Amapulse = 💚
– Tyson L.
Couldn't be happier with the experience. Makes web scraping accessible to everyone.
– Dan F.
I have nothing but huge love for Amapulse. A true game-changer for data collection.
– Anna M.